
ChatGPTの登場により、かつては時間と手間のかかっていた作業が簡素化され、一気に効率的になりました。
既に多くの方がChatGPTを取り入れ、その効果を感じているのではないでしょうか。
本記事では、ソフトウェア開発において不可欠な「ダミーデータの自動生成」に焦点を当てています。
ChatGPTの可能性を最大限に引き出し、ソフトウェア開発のプロセスを効率的に進める手助けとなればと思います。
ぜひ最後までお読みください。
ダミーデータはソフトウェア開発の足場

ソフトウェア開発プロセスにおいて、ダミーデータは建設現場の足場のような役割を果たす重要な存在と言えます。
ダミーデータがしっかりと整備されていなければ、高品質なソフトウェアの構築は難しくなります。
しかし、ダミーデータの作成は容易ではありません。データの種類、形式、必要な情報に応じてリアルなデータにより近づけるには時間と労力が必要となります。
例えば、顧客情報を含むダミーデータを作成する場合、名前、住所、メールアドレスなど、多くのフィールドに対して現実的な値を生成する必要があります。
これを手作業で行うと、大量のデータが必要な場合、膨大な時間がかかりますし、誤りも生じやすくなります。
面倒な作業はChatGPTへ
ツールにまかせる利点
ChatGPTのようなツールを利用することでダミーデータの生成が劇的に簡略化され、より多くの時間をコードの品質向上に費やすことができます。
人ではなくツールに任せることでヒューマンエラーを減らし、ダミーデータの質を一定に保つことが可能になります。
また、ChatGPTに対してダミーデータを作るための指示文(プロンプト)は自然言語で入力でき、特別な知識が無くとも実現できます。
そのため、ダミーデータを生成する人の幅を広げることも可能です。
難しいことは他ツールへ橋渡し
求められるダミーデータは多種多様なため、条件によってはChatGPT内で直接生成することが難しい場合があります。
大規模なデータセットの直接生成やパスワードなど専門のアルゴリズムを必要とするものです。
このような場合、ChatGPTは他のツールを使った生成方法を提案してくれます。
生成方法の調整は、実際にChatGPTが返す結果を見ながら対話する必要があります。同じプロンプトでも出力する件数や回答内容が一定ではないためです。
また、ChatGPTはSQLクエリを生成することができますが、高度なデータベース操作や集計クエリの生成は苦手です。
厳密なデータフォーマットが必要な場合は専用のデータ生成ツールやプログラムの方が適しています。
ダミーデータを作成してみる
例:WEBサイトへの訪問者データ
では実際にダミーデータを作成してみます。内容は架空のWEBサイトへの訪問者データとし、件数は1000件です。その他の条件をまとめたものが以下となります。
架空WEBサイト「◯✕ニュース」の訪問者データ
- さまざまな年齢層が見にくる。
- 主婦は平日昼間、子供は夕方、サラリーマンは深夜によく見にくる。
- 月間アクセス数は1000件程度。
- 記事のカテゴリは「スポーツ」「政治」「経済」の3種類。
- データは、CSV形式で出力。
この条件を自然言語で指示してみました。
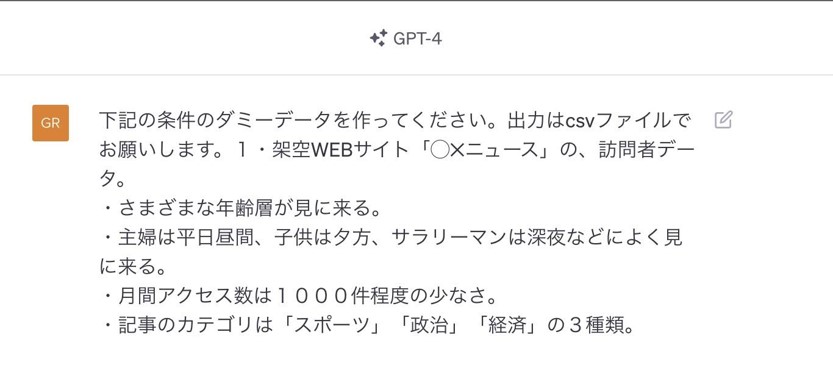
気になる結果は
最初の回答ではダミーデータの一部を表示をしてデータ構造の確認を示してくれています。
1000件のデータが出力されてから再確認するのは手間ですので出力前に確認があるのは良い点です。
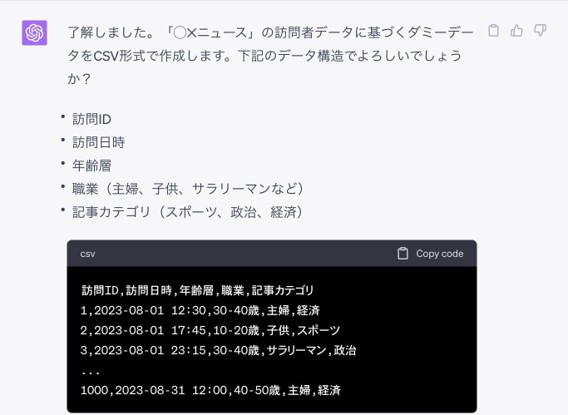
ChatGPTが返した文を見るとCSVファイルとして保存するように指示があり、1000件のデータが無事に出力されたように感じます。
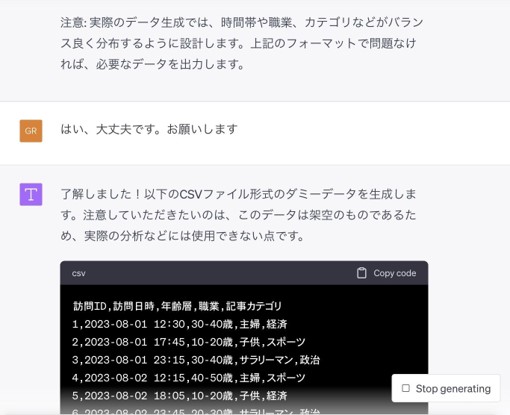

しかし、実際にテキストエディタで開いてみるとほんの一部のデータしか出力されていないことに気づきました。
ChatGPTでは文章と成果物の内容が異なることがあるため確認は必須です。新たにチャットを立て直し同じプロンプトを実行してもやはり一部のデータのみ出力される状態でした。
例:新商品の売れ行きデータ
出力の件数が足りないことは後で対応するとして、まずはダミーデータの中身を指示通りに作ることができるかを確認します。
新たなチャットで新商品の売れ行きデータを作ります。条件は以下のとおりです。
前回の新商品の売れ行きデータ
- 年齢層は20代から40代で、中心は30代
- 一人あたりの単価項目を入れる
- 新商品は1つ3500円で、最低1つから最大3つ買う人がいる
- 対象人数は2000名
- お客様タイプは、以前からのお客様、新規で会員未登録のお客様、新規で会員登録済みのお客様


ChatGPTからの回答には新たに「顧客ID」の項目が追加されています。前回同様サンプルデータが表示され、ユーザーにCSVファイルとして保存するよう書かれています。
データの変更依頼
次にデータに変更を加えられるかテストしてみます。年齢層を年齢に変更し、データの年齢もバラバラにするよう指示を追加します。
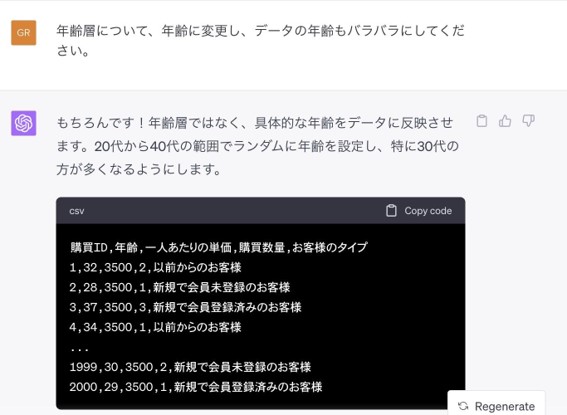
指示通り「年齢層」から「年齢」に変更されています。
このサンプルデータで出力結果が意図したものになっているか確認し、不足や変更をChatGPTとやり取りして調整するのがよいようです。
こちらでもcsvとして出力されたデータは一部のみです。ChatGPTはあくまでもサンプルとしてデータを表示しているようです。
外部ツールとの連携
Pythonでの生成を提案
データの変更が出来たため、改めてChatGPTに1000件のダミーデータ生成を依頼すると以下のような回答が返ってきました(一部省略)。
長くなるため全データを表示することはできません。
実際のデータ生成はPythonなどのプログラム言語で生成し、CSVファイルに書き込むコードを書くことが一般的です。
コードのサンプルを提供できます。

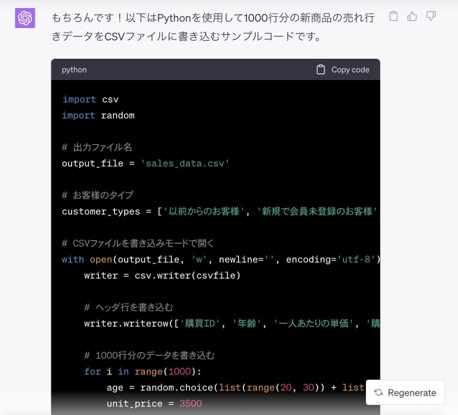
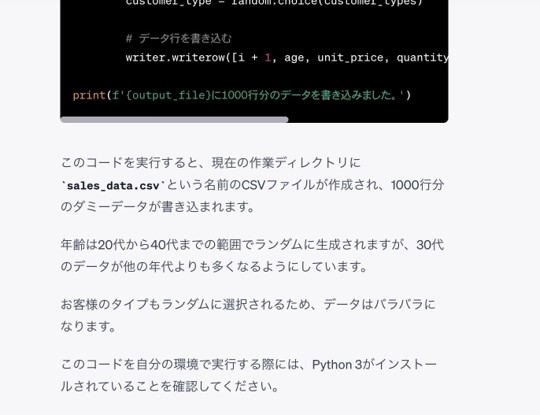
今回はPythonで生成することが提案されました。実際にPythonでコードを実行すると、問題なく指示通りのダミーデータが1000件作られ、CSVファイルにも正しく出力されました。
ChatGPT内で処理できる規模には制限があるようです。以前、例示用データとして項目が3つのデータを40件ほど依頼した際にはChatGPT内で出力することができました。
そのため、作りたいデータの件数や複雑さに応じて回答が変わることを理解しておくとよいでしょう。
対応している他のプログラム
今回のテストではPython用のコードが提示されましたが、他に対応しているプログラムをChatGPTに尋ねたところ、R言語、JavaScript、SQL、Excelのマクロ(VBA)という回答が返ってきました。
ダミーデータの種類によっては最初に提案される外部ツールが変わる可能性もありそうです。
ChatGPTにプログラムを選ぶ基準について確認すると、多目的性や豊富なライブラリがあることからPythonを選択することが増えるということでした。
もちろんそれぞれの開発環境や目的に応じてプログラムを指定することも可能なため、開発しているソフトウェア環境に合わせて柔軟な対応が期待できます。
以上のことから、ChatGPTにダミーデータ作成を依頼すれば、最適な形でデータや、データの作成方法を示してくれるということです。
まとめ:ChatGPT×外部ツールでより便利に
今回の記事では、ChatGPTを使用してダミーデータを自動で生成する方法に焦点を当てました。
ダミーデータはソフトウェア開発において不可欠ですが手間のかかる作業でもありました。しかしChatGPTにより、この課題を劇的に簡素化することが可能になりました。
記事では具体的なステップと注意点をまとめました。
ダミーデータの種類や生成条件によっては他のツールの力を借りることもありますが、Python、R言語など、さまざまなプログラム言語やツールに対応しており柔軟性が高いと言えます。
ソフトウェア開発がスムーズに進行できるようぜひ取り入れてみてください。









コメント