
東京工業大学の研究チームと産業技術総合研究所は2023年12月19日に、日本語に強い大規模言語モデル(LLM)「Swallow」を公開しました。
この記事ではSwallowの詳細についてご紹介します。
Swallowとは?


日本の産業技術総合研究所と東京工業大学の共同研究チームが開発した、日本語に特化した大規模言語モデル(LLM)です。
米Metaが開発した「Llama 2シリーズ」を基にしており、日本語処理能力が大幅に強化されています。
SwallowのライセンスはLlama 2のLLAMA 2 Community Licenseを継承しています。このライセンスに従う限りにおいては、研究および商業目的での利用が可能です。
モデルの種類
70億(7B)、130億(13B)、700億(70B)のパラメータを持つ3種類の継続事前学習モデル(base)とそれぞれに指示チューニングを施した言語モデル(instruct)の計6種類を提供しています。
特徴:日本語能力の向上

Llama 2は日本語に対応していましたが、事前学習データの約90%が英語で、日本語の割合は全体の約0.10%に留まることもあり、日本語での読み書きが弱点でした。
そこで研究チームは、非営利団体のコモンクロール(Common Crawl)が配布しているアーカイブから日本語のテキストを独自に抽出・精錬し、約3121億文字(約1.73億ページ)からなる日本語Webコーパスを構築しました。
Llama 2の7B、13B、70Bのモデルをベースに、日本語Webコーパスと英語のコーパスを9:1で混ぜたデータで継続事前学習を実施し、元々の言語モデルの能力を活かしながら日本語能力の改善に成功しました。
加えて、1万6,000件の日本語トークンをLlama 2のトークナイザに追加することで、日本語テキストのトークン長を56.2%削減。
LLMの学習に必要な計算予算を有効活用できるようになり、結果の出力時間の短縮や性能向上を図れるとしています。
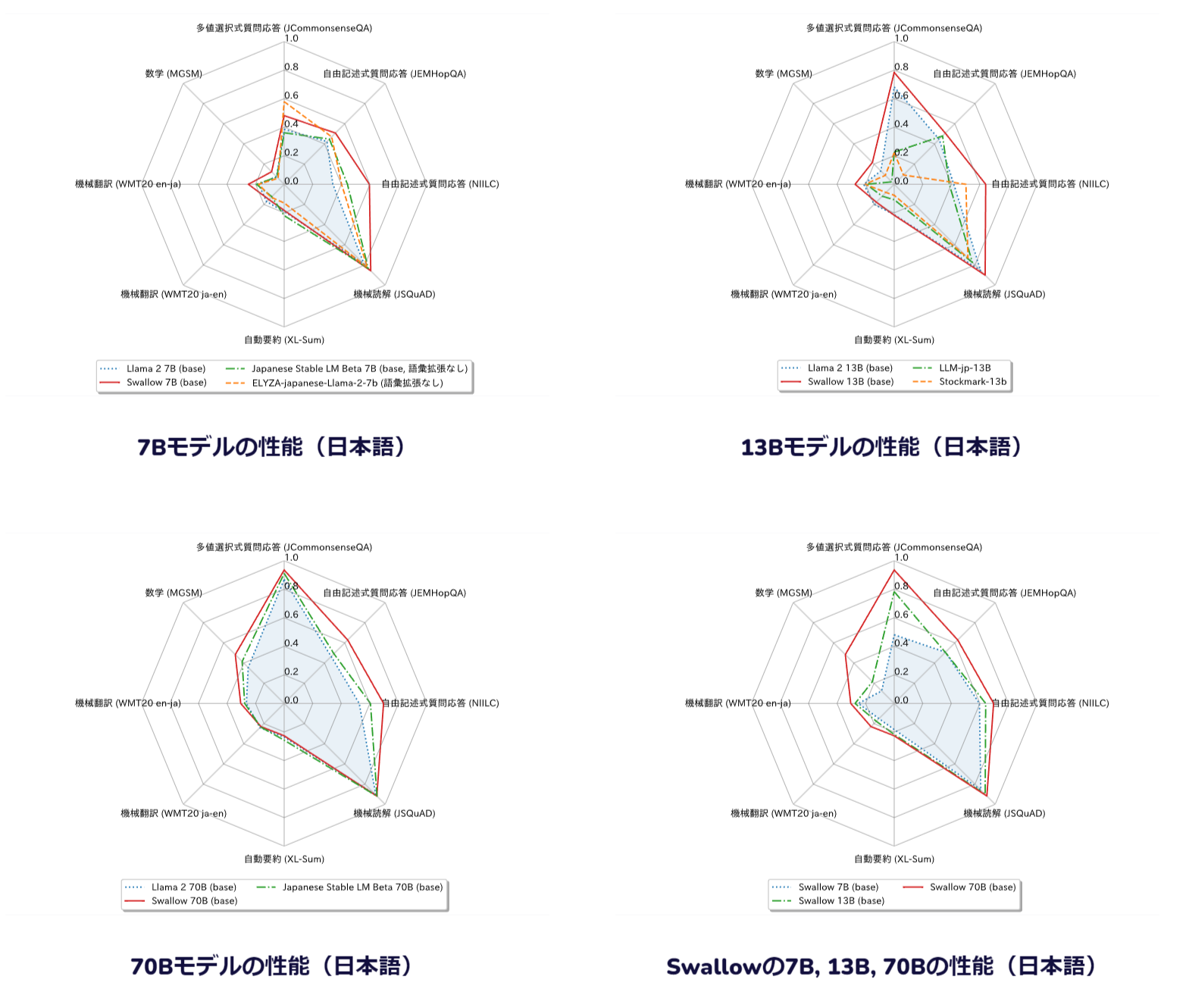
Swallowの性能

Llama 2に継続事前学習を行ったモデルで日本語の性能の比較結果です。
13Bのモデルは比較対象が無いため、日本語でフルスクラッチで学習したモデルとの比較を含んでおり、この結果から、Swallowは継続事前学習で日本語の能力を着実に伸ばしたこと、フルスクラッチで事前学習したモデルよりも高い性能を持つことが分かります。
続いて、英語の性能の比較結果です。

Swallowの英語の性能は元のモデルよりも若干低下しています。
原因として、Swallowでは継続事前学習に日本語と英語のテキストを混ぜたデータを利用していますが、他のモデルでよく用いられる混合比1:1ではなく、日本語を重視した9:1を採用しているためだと考えられます。
この詳細に関しては、今後の追加実験で明らかになる予定です。
まとめ:今後の展開

産業分野では、外部の企業に依存せずに自社で大規模言語モデルを運用できるだけでなく、特定のタスクに特化したモデルにチューニングすることが可能です。
今回のSwallowの公開により、高度な日本語処理が求められる多くの場面において、対話システムをはじめとしたAI技術の活用が期待できます。

コメント